Functional Programming: map
One of the famous functional programming concepts is
higher-order functions,
which are functions that either take functions as input or return functions
as output. map is one of the most popular higher-order functions, and also
one of the most useful. You can find it in popular languages like
Python and
JavaScript. R also has many variants of map.
This tutorial will explain map in general and give an overview of available
implementations in R. For a more detailed look, I recommend reading the
R for Data Science chapter on iteration.
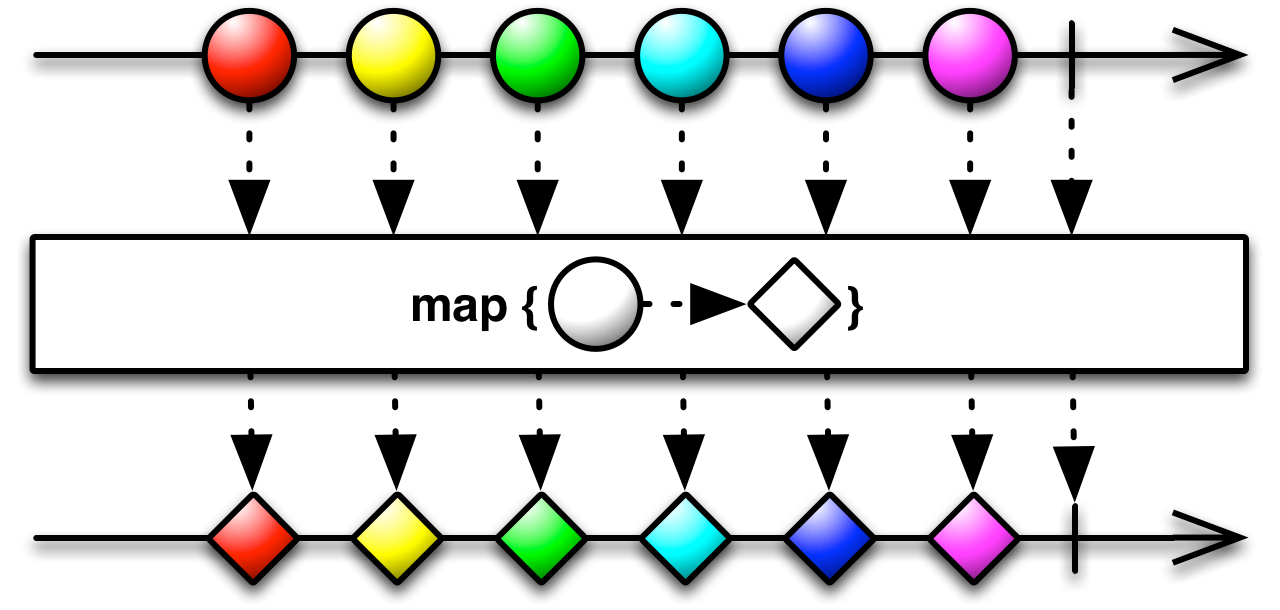 (Image source: http://keitheis.github.io/reactive-programming-in-python/)
(Image source: http://keitheis.github.io/reactive-programming-in-python/)
What is map?
To put it shortly, map takes a function and a collection (e.g. list) as input,
calls the function on each element of the collection, then returns as output a
new collection of the results of such calls.
Let’s say that I have:
- a function
incrementthat simply takes a number and adds 1 to it - a colelction of numbers from 1 to 5
Calling map with the function increment and the number list will give back a
new list of numbers from 2 to 6.
Why is it useful?
Anyone familiar with basic programming concepts should think of for loops when
they want to iterate over a collection. But for loops contain too much code
boilerplate and also requires initializing new variables like the “i” that gets
incremented with each iteration and an empty collection that will take the
new results. So, map is more concise and elegant than for loops.
Side note: this constrast is basically the difference between declarative programming and imperative programming, where the former says what the programmer wants to do and the latter explains to the computer more low-level steps on how to do it.
How to implement it in R?
Using map-like functions while using R in a statistics/data science setting
is almost always about iterating with some function over columns of a data
frame. The base R option for iterating (with a function) over columns of a data
frame is the function sapply().
For example, one quick way to identify the column types without having to
print a lot of extra output, like str() or summary(), is by doing
something like this:
sapply(iris, class)
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# "numeric" "numeric" "numeric" "numeric" "factor"
So, I applied the function class() on each column of the data frame iris
and got a simple output of the class (data type) of every column. The same
thing can be done with mean() or any other function that expects a vector
(remember that iterating one each column means iterating on individual
vectors).
sapply(iris, mean)
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 5.843333 3.057333 3.758000 1.199333 NA
Notice that the parentheses are not written because I am not calling the function – I am passing it as an argument.
Another direct equivalent for this purpose is purrr::map(). It behaves
almost the same, except the following:
map()returns a list instead of the behavior ofsapply()which tries to “simplify” the output into a vector.- The package
purrrhas a set ofmap_*functions that enforce certain output types:map_dbl()ensures the output is a double (numeric) vector,map_df()ensures the output is a data frame, and so on.
iris_means <- map(iris, mean)
class(iris_means)
# [1] "list"
iris_means
# $Sepal.Length
# [1] 5.843333
#
# $Sepal.Width
# [1] 3.057333
#
# $Petal.Length
# [1] 3.758
#
# $Petal.Width
# [1] 1.199333
#
# $Species
# [1] NA
iris_means_dbl <- map_dbl(iris, mean)
class(iris_means_dbl)
# [1] "numeric"
iris_means_dbl
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 5.843333 3.057333 3.758000 1.199333 NA
Anonymous functions
Sometimes the function you want to map over columns is not already defined
with a name. In this case, you have to write your own function. But instead
of defining a function in your script and using it only once in your
iteration code, you could actually write an anonymous function as the
function argument to sapply() or map(). If you are familiar with writing
your own functions, it is the same except that you do not assign that
function to a variable.
See this example:
sapply(iris,
function(var) { is.numeric(var) | is.character(var) })
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# TRUE TRUE TRUE TRUE FALSE
I wrote a function that returns TRUE if the variable is a numeric or
character vector. That function has no name (i.e. anonymous) and will only be
used in the sapply() call.
Now purrr has special syntax for writing anonymous functions. While the
previously described syntax is perfectly valid for map(), the special
syntax provided by purrr is more concise if you would prefer learning and
using it.
map_lgl(iris,
~ is.numeric(.x) | is.character(.x))
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# TRUE TRUE TRUE TRUE FALSE
The anonymous function syntax here starts with a tilde followed by your own
function body, using “.x” as the argument.
Bonus: map in Python and JavaScript
- Python:
list(map(lambda x: x + 1, [1, 2, 3, 4, 5]))
# [2, 3, 4, 5, 6]
- JavaScript:
[1, 2, 3, 4, 5].map((x) => x + 1);
// [2, 3, 4, 5, 6]
I personally like JavaScript’s arrow function syntax for writing anonymous functions.
So, this was map! The concept behind it is relatively simple but really
elegant, and it should save you a lot of time and code duplication if you get
to use it often. Also, since it is a popular concept and already implemented
in major languages, you can easily transfer your knowledge between languages.