Text Analysis Phase 2: Python
I have been an R purist through my whole learning journey, but now I am picking up Python. Although I did play with a lot of languages, including Python, my goal was never to make something practical with them. But now, I felt it was necessary to switch to Python for real to learn more natural language processing. I don’t believe R is lacking in power in that domain, but I know the Python world is richer with educational resources.
In this post, I will share some of my thoughts on different parts of the learning experience.
First resource (not really)
Just as I started learning on R with a book, I am did the same with Python with The NLTK book by Steven Bird. This book quickly caught my interest because: 1) it is written by the developers of the library NLTK to teach how to use it, and 2) the content assumes no prior programming experience and teaches Python, not just the library.
I finished 2 chapters so far, and I can’t help but compare the learning experience of both resources.
- Density: The R book had much less content per chapter and was more hands-on. I believe this is kind of a common theme of the “modern” R books. The NLTK book, on the other hand, was much more detailed. It was written in a way to allow its use as a textbook for an academic curriculum with no requirement of prior programming knowledge.
- Programming: The tidy text book and package are about a
“tidy” format of text, which
is created with a simple
unnest_tokens()call and allows analysis with the popular Tidyverse tools. So, there isn’t much new stuff to learn beyond tidying text data. NLTK deals at a lower level with list- and dictionary-like objects, which means that most of the processing algorithms are written with stuff from the standard library. (More on that later.)
Jupyter Notebooks
I chose to code along the book and solve its exercises in Jupyter Notebooks. (I have them hosted on GitHub). They seemed like a convenient place to learn as they are interactive and, more or less, self-contained so I could print code results (including plots) in place. So, they are more suitable for someone playing around with code. Plus, I wanted to get started right away and didn’t want to spend time setting up Vim.
To be honest, I don’t like Jupyter Notebooks very much. Yes, I do praise their
convenience, but I wouldn’t use them in a real project except for the initial
exploratory work. There is also this little gripe I have about people publishing
notebooks on GitHub with absolutely no Markdown content or plots. How different
is it from a simple .py script now?
Data Structures and Algorithms
It came as a (pleasant) surprise that I learned many things in Python that are
not specific to NLTK or text analysis. I had practice with a lot of the
fundamentals, dealing with dictionaries and lists, iteration, functional
programming, refactoring for efficiency, and a little matplotlib.
The part I captured below is a nice demonstration of what I learned in Python coding. The first algorithm I wrote iterates over a list, over another list. This yields a number of iterations equal to the product of the length of the two lists. It took more than 30 minutes before I actually stopped it from running. Then I rewrote it by making another algorithm that uses exactly one dictionary and no nested iterations. It took about 500 milliseconds.
From half an hour to half a second!
Also, I wrote the dictionary-based algorithm in a functional form and a list comprehension form. I love list comprehensions in Python: they make a really elegant way to make a list with iteration.
Application
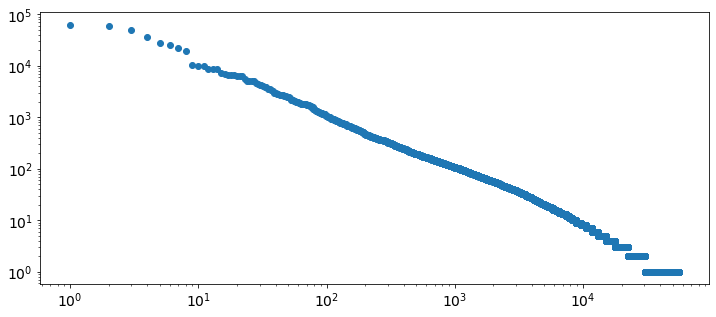
Exercises in the NLTK book included some relatively practical text analysis
questions. One of them was Zipf’s law in which I created a plot similar to the
one I previously made with R but much
simpler and uglier. I need to up my game with matplotlib.
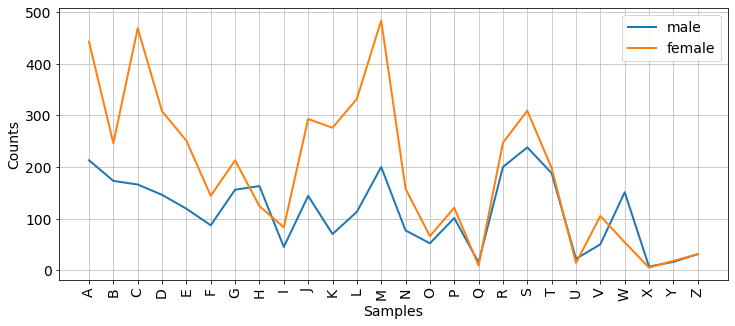
Another one was to see the frequency of name initials in male and female names.
So far, I really enjoyed working with Python, both as a text analysis tool and a programming language in general. It has a clean syntax and cool stuff like list (and dict) comprehensions. But what I learned so far in terms of NLP is still simple. I will keep studying from the NLTK book, and surely learn more Python in process.